Structure des dossiers de stockage
David Nortes Martinez
directory_structure_fr.RmdIntroduction
Les bases de données externes que floodam.data permet de
télécharger sont régulièrement mises à jour. Leur stockage externe est
organisé par version, millésime et étendue géographique de façon variée
selon les fournisseurs voire les bases de données.
La bibliothèque floodam.data est conçue de manière à ce
que l’utilisateur n’ait pas à se préoccuper de l’organisation de ces
informations ; floodam.data s’occupe de tout, du
téléchargement à la reformulation et au stockage. Pour ce faire, le flux
de travail de la bibliothèque définit et utilise une structure de
répertoire très spécifique qui sert un double objectif :
- Organiser l’information par base de données, par millésime et par emplacement géographique.
- Gérer les noms de fichiers et de dossiers de manière programmatique.
Organisation lors du téléchargement
Lorsque les bases de données sont téléchargées à l’aide d’une
fonction download_*(), le flux de travail génère une
structure de répertoire à deux niveaux :
- premier niveau : nom de la base de données
- deuxième niveau : millésime
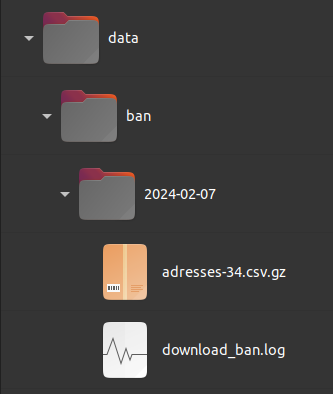
Ainsi, si, par exemple, nous voulons traiter la base de données BAN
(Base Adresse nationale), la fonction
download_ban() crée la structure de répertoire suivante
dans le dossier fourni au paramètre destination (par
exemple data)
library(floodam.data)
output = "data"
download_ban(
destination = output,
department = 34
)
Organisation lors des adaptations
Les fonctions de la famille adapt_*() attendent cette
structure de répertoire à partir de laquelle elles peuvent acquérir des
informations clés sur les types de données et leur millésime. Elles vont
répliquer la structure pour stocker leurs propres résultats.
En continuant avec notre exemple, nous utilisons maintenant la
fonction adapt_ban() pour traiter la base de données que
nous avons téléchargée dans le dossier data, dans un nouveau
dossier appelé adapted.
adapt_ban(
origin = file.path(output, "ban", "2024-01-31"),
destination = file.path(output, "adapted")
)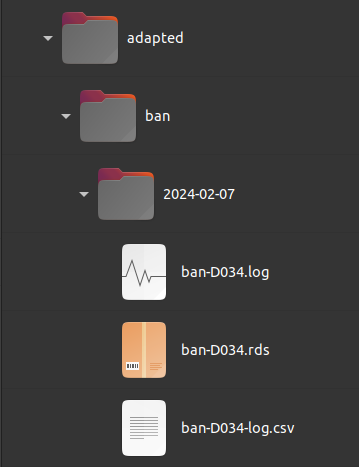
Comme nous pouvons le voir, la fonction adapt_ban()
génère, d’une part, la même structure de répertoire que
download_ban() et, d’autre part, elle utilise le nom de
dossier ban pour nommer le fichier de sortie en combinaison
avec la référence géographique (D034).
Remarque importante
Si, pour une raison quelconque, l’utilisateur n’utilise pas le flux de travail de la bibliothèque, la structure de répertoire spécifique attendue par chaque fonction doit être construite manuellement comme suit :
- Premier niveau : nom de la base de données
- Deuxième niveau : millésime
Dans le cas contraire, les espaces de stockage créés peuvent être inattendus.